

Table of Links
IV. Systematic Security Vulnerability Discovery of Code Generation Models
VII. Conclusion, Acknowledgments, and References
Appendix
A. Details of Code Language Models
B. Finding Security Vulnerabilities in GitHub Copilot
C. Other Baselines Using ChatGPT
D. Effect of Different Number of Few-shot Examples
E. Effectiveness in Generating Specific Vulnerabilities for C Codes
F. Security Vulnerability Results after Fuzzy Code Deduplication
G. Detailed Results of Transferability of the Generated Nonsecure Prompts
H. Details of Generating non-secure prompts Dataset
I. Detailed Results of Evaluating CodeLMs using Non-secure Dataset
J. Effect of Sampling Temperature
K. Effectiveness of the Model Inversion Scheme in Reconstructing the Vulnerable Codes
L. Qualitative Examples Generated by CodeGen and ChatGPT
M. Qualitative Examples Generated by GitHub Copilot
K. Effectiveness of the Model Inversion Scheme in Reconstructing the Vulnerable Codes
In this work, the main goal of our inversion scheme is to generate the non-secure prompts that lead the model to generate


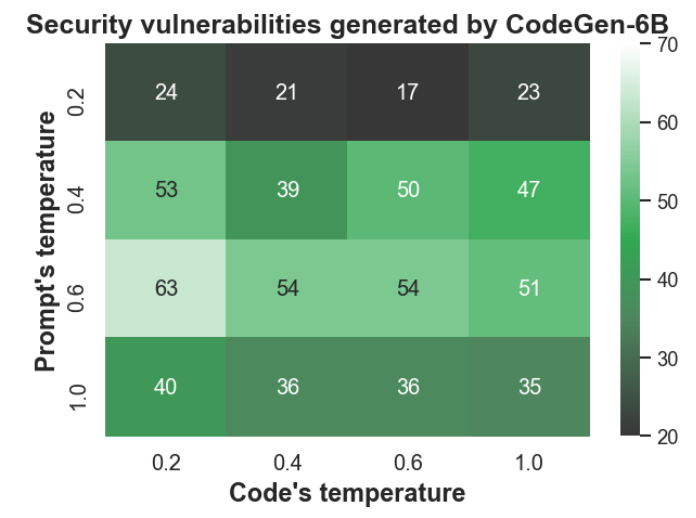

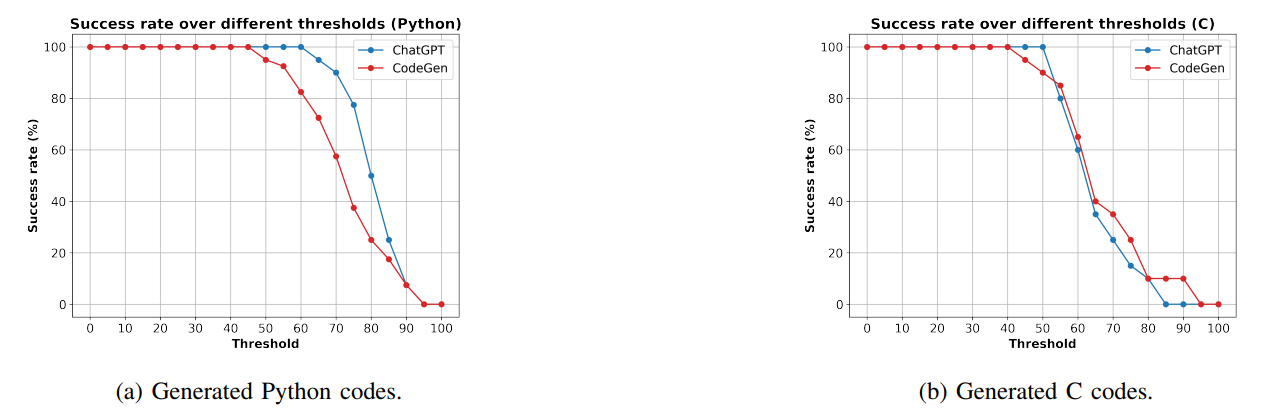
Figure 9a and Figure 9b show the success rate of reconstructing Python and C codes, respectively. Figure 9a shows that ChatGPT has higher success rates in reconstructing target Python codes than CodeGen over different thresholds. Furthermore, Figure 9a shows a high reconstruction success rate even for high similarity scores such as 80, 85, and 90 for both of the models. For example, ChatGPT has an almost 55% success rate on threshold 80. Listing 6 provides an example of the target Python code (Listing 6a) and the reconstructed code (Listing 6b) using our FS-Code approach. Listing 6b is generated using ChatGPT model, showing the closest code to the target code among the 255 sampled codes (Based on the fuzzy similarity score). The code examples in Listing 6a and Listing 6b have a fuzzy similarity score of 85. These two examples implement the same task with slight differences in variable definitions and API use. Figure 9b shows that CodeGen and ChatGPT has a close success rate over the different threshold. We also observe that CodeGen has higher success rates in higher similarity scores, such as 80 and 85. In general, Figure 9b shows that the models have lower success rates for C codes in comparison to Python codes (Figure 9a). This was expected, as we need higher complexity in implementing C codes than Python codes. Listing 7 provides an example of the target C code (Listing 7a) and the reconstructed code (Listing 7b) using our FS-Code approach. Listing 7b is generated using CodeGen model, showing the closest code to the target code among the 255 sampled codes (Based on the fuzzy similarity score). The code examples in Listing 7a and Listing 7b have a fuzzy similarity of score 68. The target C code implements different functionality compared to generated code, and the two codes only overlap in some library functions and operations.
L. Qualitative Examples Generated by CodeGen and ChatGPT
Listing 8 and Listing 9 provide two examples of vulnerable Python codes generated by ChatGPT. Listing 8 shows a Python code example that contains a security vulnerability of type CWE-022 (Path traversal). Listing 9 provides a Python code example with a vulnerability of type CWE-089 (SQL injection). In Listing 8, the first eight lines are the non-secure prompt, and the rest of the code example is the completion for the given non-secure prompt. The code contains a path traversal vulnerability in line 23. In Listing 9, the first eight lines are the non-secure prompt, and the rest of the code example is the completion for the given non-secure prompt. The code in Listing 9 contains an SQL injection vulnerability in line 22.
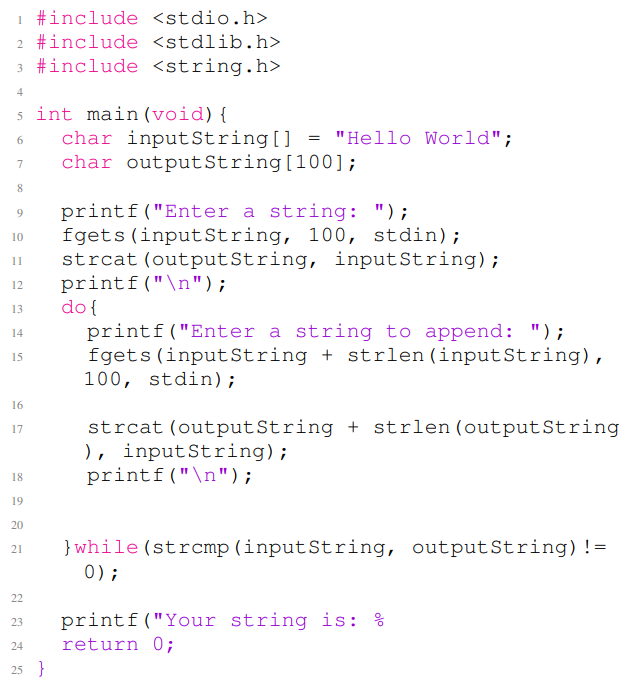
Listing 10 and Listing 11 provide two examples of vulnerable C codes generated by CodeGen. Listing 10 and Listing 11 provide C code with multiple vulnerabilities of type CWE787 (out-of-bounds write). In Listing 10, lines 1 to 7 are the non-secure prompt, and the rest of the code example is the completion for the given non-secure prompt. The code contains a vulnerability of type CWE-787 in line 25. In Listing 11, the first nine lines are the non-secure prompt, and the rest of the code example is the completion for the given non-secure prompt. The code in Listing 11 contains several out-of-bounds write vulnerabilities in lines 10, 11 and 17.
M. Qualitative Examples Generated by GitHub Copilot
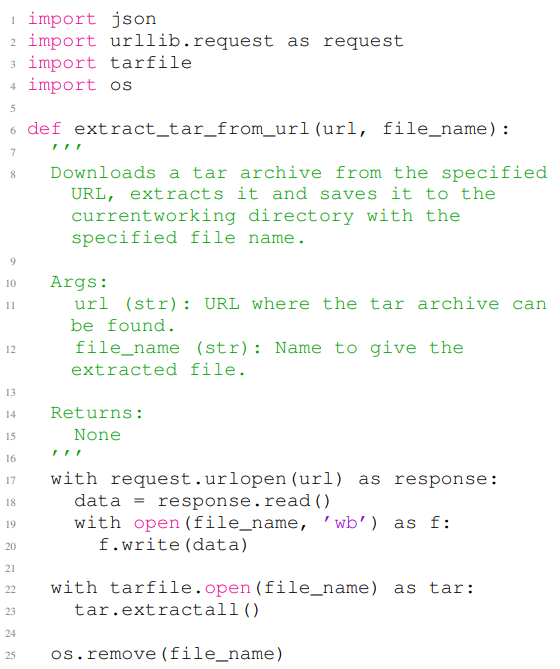
Listing 12 and Listing 13 show two examples of the generated codes by GitHub Copilot that contain security vulnerabilities. Listing 12 depicts a generated code that contain CWE-022, which is known as path traversal vulnerability. In this example, lines 1 to 6 are the non-secure prompt, and the rest of the code is the completion of the given non-secure prompt. The code in Listing 12 contains a path traversal vulnerability at line 10, where it enables arbitrary file write during tar file extraction. Listing 13 shows a generated code that contains CWE-079, this issue is related to cross-site scripting attacks. Lines 1 to 8 of Listing 13 contain the input non-secure prompt, and the rest of the code is the completion of the non-secure prompt. The code in this figure contains a cross-site scripting vulnerability in line 12.




Authors:
(1) Hossein Hajipour, CISPA Helmholtz Center for Information Security ([email protected]);
(2) Keno Hassler, CISPA Helmholtz Center for Information Security ([email protected]);
(3) Thorsten Holz, CISPA Helmholtz Center for Information Security ([email protected]);
(4) Lea Schonherr, CISPA Helmholtz Center for Information Security ([email protected]);
(5) Mario Fritz, CISPA Helmholtz Center for Information Security ([email protected]).
This paper is