
Table of Links
2.2 The communication protocol
3 Pair programming with ChatGPT
5 Conclusion and Acknowledgments
Appendix A: The solution in Python
4 Summary and discussion
During the development of the working code solving our example task, we observed a considerable list of advantages from which we can benefit while pair programming with ChatGPT. In particular:
-
ChatGPT can save time by quickly and concisely summarizing basic facts about the topic of our interest, e.g., formulas or application examples, as illustrated in Section 3.1.
-
If ChatGPT is not able to provide a correct solution due to a lack of or incorrect knowledge, we can feed it with the correct knowledge, and make it use it to provide a correct solution. In Section 3.2, this approach led ChatGPT to produce a function evaluating the PDF of the copula model in three different programming languages. In Section 3.4, a working code for sampling from the copula model is generated once ChatGPT was fed by the related non-trivial theory. Particularly the latter example shows that ChatGPT is able to understand even relatively complex concepts, and clearly demonstrates that it can be applied in cases when it faces unknown concepts.
-
ChatGPT saves time by mapping simple concepts, e.g., sampling from the standard exponential and gamma distributions, to existing code (libraries, APIs, or functions) available for a given programming language, as illustrated in Section 3.4.
-
The more common the task to solve, the more successful ChatGPT in generating a correct solution. This is illustrated, e.g., in Section 3.3, where we immediately obtained code implementing the maximal likelihood estimator by a simple prompt like write code for the maximum likelihood estimator of that parameter. Another example is the transpilation of the MATLAB solution to Python in Section 3.5, or the optimization of existing code for parallel computing on CPUs and GPUs in Section 3.6.
-
ChatGPT can help in cases when an error is thrown after executing the generated code. In Section 3.4, we have seen that it not only detected what was wrong, but provided a corrected solution. Apart from saving time needed to search and fix the error, this can be crucial particularly for less experienced programmers, who could find the error too complex and eventually give up. ChatGPT helped us roughly with 1/3 of the errors we encountered. Even if not perfect, this is substantially better than no help at all.
-
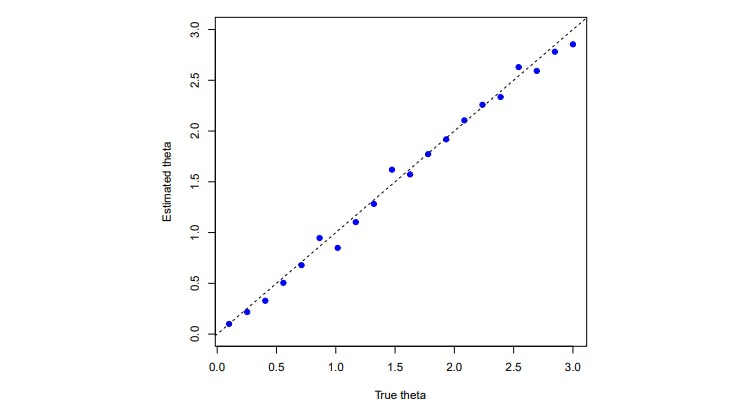
ChatGPT can help with creating visualizations. In Section 3.5, it generated a visualization suggesting that all previously generated code is correct. Even if we have not asked for it, the visualization included all the typical trivia like labels, benchmarks, limits, legends, etc.
-
ChatGPT at least partially understands the underlying concepts of what we are doing. Without asking it to do so, it added to the visualization the plot of the identity (see Section 3.5), suggesting that it is aware of us trying to estimating the true value of some parameter.
-
ChatGPT can transpile code from one programming language to another also with high-level prompts like Code it in Python and And in R, demonstrated in Section 3.5. The same section also shows that if the transpilation fails (which happened with the transpilation to R), it is possible to use a quick “brute-force” solution that also accomplished the task.
-
ChatGPT can optimize the already generated code, e.g., for parallel computations. By prompting optimize that for parallel computing on CPUs, we immediately got the optimized version of the sample-estimate procedure developed in Section 3.5; see Section 3.6.1. The same section also shows that a high-level prompt like Create a demonstration of this optimization can result in code showing the impact of the optimization, again including the typically tedious but necessary trivia like labels, etc. Similarly, such an optimization together with a simple demonstration was generated also for computations on GPUs; see Section 3.6.2.
-
ChatGPT follows proper coding techniques, so the user can genuinely learn them too. We observed that the produced code is properly commented, indented, modularized, avoids code duplicities, etc.
-
ChatGPT helps the user to get familiar with the produced code faster. When providing code, ChatGPT typically surrounds it by further information explaining its main features. To save space, we mostly cut this out, however, an example can be found, e.g., in Section 3.4 in connection to the error message thrown by the simple check code.
We have also seen that pair programming with ChatGPT brings several disadvantages, which should be carefully considered. Let us summarize them and discuss possibilities to mitigate them:
-
ChatGPT in its current version (early 2023) is poor in reasoning; see Section 3.1. On two examples, we demonstrated how it responses with contradicting answers to the same question. We particularly highlight the case when it first answered yes and then no to the same question. Also, we demonstrated how dangerous this could be in quantitative reasoning, where it generated incorrect formulas that looked very similar to correct ones; see the PDF derivation in Section 3.2. In order to mitigate this problem, a lot of effort can be currently observed. One of the most 25 promising examples in the direction of quantitative reasoning is Minerva (Lewkowycz et al., 2022), an LLM based on the PaLM general language models (Chowdhery et al., 2022) with up to 540 billion of parameters. This model, released in June 2022, gained its attention by scoring 50% on questions in the MATH data set, which was a significant improvement of the state-of-the-art performance on STEM evaluation datasets; see Table 3 therein. In other works, the authors develop models fine-tuned for understanding mathematical formulas (Peng et al., 2021), or employ deep neural networks in mathematical tasks like symbolic integration or solving differential equations (Lample and Charton, 2019). Another way of mitigating the problem can be trying to exploit at maximum the current LLMs by carefully adjusting the prompt in order to get more reliable answers. This increasingly popular technique, called prompt engineering, involves special techniques to improve reliability when the model fails on a task , and can substantially improve the solution, e.g., for simple math problems, just by adding “Let’s think step by step.” at the end of the prompt. Note that we tried this technique in the example considering the tail dependence of the survival Clayton copula in Section 3.1, however, without success, probably because the underlying concepts go beyond simple mathematics.
-
If ChatGPT lacks the necessary knowledge or possesses incorrect knowledge, it may generate an incorrect solution without any indication to the user. As illustrated in Section 3.4, after asking it for code for sampling from a Clayton copula model, ChatGPT first generated two routines, which were resembling proper sampling algorithms, but were entirely incorrect. Due to the opacity of the current state-of-the-art LLMs that contain tens or even hundreds of billions of parameters, the correctness of the solution can hardly be guaranteed in all cases. While there may be efforts to develop more explainable LLMs, it is unlikely that the fundamental challenges related to the complexity of language and the massive amounts of data required for training will be completely overcome. Therefore, it is essential for a human expert in the field to always verify the output generated by the model.
-
Specifically, ChatGPT tends to be less successful in producing accurate solutions for tasks that are less common. This means that the opposite of advantage 4. also applies. In Section 3.2, this is demonstrated through the probability density function (PDF) of the copula model. In Section 3.4, through the sampling algorithm. To solve these issues, we provided the required theory to ChatGPT, which led to a correct solution, see the same two sections.
-
ChatGPT does not have any memory. If the conversation is too long, and thus does not fit within ChatGPT’s context window, it seems that the model has forgotten some parts of the conversation. This, together with ways how to mitigate this issue, has already been discussed in Section 2.2.
Apart from ChatGPT, there are several other language models that are capable of generating code solutions from natural language inputs. One notable example is AlphaCode (Li et al., 2022), which achieved on average a ranking of top 54.3% in competitions with more than 5,000 participants on recent programming competitions on the platform Codeforces. Recently, AlphaCode has been made publicly available[15], including example solutions from the mentioned contest. Another example is OpenAI Codex[16], already mentioned in the introduction. In contrast to ChatGPT, these models have been developed particularly for code generation. On the one hand, it is thus possible that one can generate solutions that are better than those generated with ChatGPT. It would thus be interesting future research to compare, e.g., the successfulness of these models for solving the tasks considered in this work.
On the other hand, ChatGPT might be more convenient for many users than these models as it allows for interaction during the coding process. Unlike AlphaCode and OpenAI Codex, which generate code snippets based on natural language inputs without any further interaction, ChatGPT allows users to provide feedback and adjust the generated code in real-time. This interaction can be beneficial for several reasons. First, it allows users to clarify their intent and ensures that the generated code aligns with their goals. For example, as we have seen in Section 3.4 that considers the sampling from a Clayton copula model, if a user requests a specific functionality and the generated code does not quite match what they had in mind, the user can provide feedback to ChatGPT to adjust the code accordingly. Second, the interaction with ChatGPT can help users learn more about programming and improve their coding skills. By engaging in a dialogue with ChatGPT, users can gain insights into the logic and structure of the code they are generating, and learn how to improve their code in the future. For example, in Section 3.6.2, we could genuinely learn how to convert existing code for parallel computing on GPUs. Finally, the interaction with ChatGPT can help users troubleshoot errors and debug their code more effectively. As we have seen in Section 3.4, ChatGPT can recognize common programming mistakes, and provide feedback that helps users to identify and fix errors in their code. These reasons, together with the fact that ChatGPT can be conveniently accessed through a web portal, led us to choose ChatGPT as our pair programming AI partner.
Author:
(1) Jan G´orecki, Department of Informatics and Mathematics, Silesian University in Opava, Univerzitnı namestı 1934/3, 733 40 Karvina, Czech Republic ([email protected]).
This paper is
[14] https://github.com/openai/openai-cookbook/blob/main/techniques to improve reliability.md
[15] https://github.com/deepmind/code contests
[16] https://openai.com/blog/openai-codex/