

Table of Links
IV. Systematic Security Vulnerability Discovery of Code Generation Models
VII. Conclusion, Acknowledgments, and References
Appendix
A. Details of Code Language Models
B. Finding Security Vulnerabilities in GitHub Copilot
C. Other Baselines Using ChatGPT
D. Effect of Different Number of Few-shot Examples
E. Effectiveness in Generating Specific Vulnerabilities for C Codes
F. Security Vulnerability Results after Fuzzy Code Deduplication
G. Detailed Results of Transferability of the Generated Nonsecure Prompts
H. Details of Generating non-secure prompts Dataset
I. Detailed Results of Evaluating CodeLMs using Non-secure Dataset
J. Effect of Sampling Temperature
K. Effectiveness of the Model Inversion Scheme in Reconstructing the Vulnerable Codes
L. Qualitative Examples Generated by CodeGen and ChatGPT
M. Qualitative Examples Generated by GitHub Copilot
A. Details of Code Language Models
Large language models make a major advancement in current deep learning developments. With increasing size, their learning capacity allows them to be applied to a wide range of tasks, including code generation for AI-assisted pair programming. Given a prompt describing the function, the model generates suitable code. Besides open-source models, e. g. CodeGen [6], there are also black-box models such as ChatGPT [4], and Codex [5][1]
In this work, to evaluate our approach, we focus on two different models, namely CodeGen and ChatGPT. Additionally, we assess three other code language models using our nonsecure prompts dataset. Below, we present detailed information about these models.
a) CodeGen: CodeGen is a collection of models with different sizes for code synthesis [6]. Throughout this paper, all experiments are performed with the 6 billion parameters. The transformer-based autoregressive language model is trained on natural language and programming language consisting of a collection of three data sets and includes GitHub repositories (THEPILE), a multilingual dataset (BIGQUERY), and a monolingual dataset in Python (BIGPYTHON).
b) StarCoder: StarCoder [24] models are developed as large language models for codes trained on data from GitHub, which include more than 80 programming languages. The model comes in various versions, such as StarCoderBase and StarCoder. StarCoder is the fine-tuned version of StarCoderBase specifically trained using Python code data. In our experiment, we utilize StarCoderBase, which has 7 billion parameters.
c) Code Llama: Code Llama [12] is a family of LLM for code developed based on Llama 2 models [61]. The models are designed using decoder-only architectures with 7B, 13B, and 34B parameters. Code Llama encompasses different versions tailored for a wide array of tasks and applications, including the foundational model, specialized models for Python code, and instruction-tuned models. In our experiments, we generate the non-secure prompts using Code Llama (without instruction tuning), which has 34 billion parameters. Additionally, we assess the instruction-tuned version of Code Llama, which has 13 billion parameters, using our proposed dataset of non-secure prompts.
d) WizardCoder: WizardCoder enhances code language models by adapting the Evol-Instruct [62] method to the domain of source code data [56]. More specifically, this method adapts Evol-Instruct [62] to generate complex code-related instruction and employ the generated data to fine-tune the code language models. In our experiment, we evaluate WizardCoder with 15B parameters using our set of non-secure prompts. It is important to note that WizardCoder is built upon the StarCoder15B model, and it is further fine-tuned using their generated instructions [56].
e) ChatGPT: The ChatGPT model is a variant of GPT3.5 [1] models, a set of models that improve on top of GPT-3 and can generate and understand natural language and codes. GPT-3.5 models are fine-tuned by supervised and reinforcement learning approaches with the assistance of human feedback [4]. GPT-3.5 models are trained to follow the user’s instruction(s), and it has been shown that these models can follow the user’s instructions to summarize the code and answer questions about the codes [3]. In all of our experiments, we use gpt-3.5-turbo-0301 version of ChatGPT provided by OpenAI API [52].
It is worth noting that we utilize GPT-4 [54] as one of the models to generate the non-secure prompts of our dataset. We opted for this model because of its exceptional performance in program generation tasks. In the procedure of generating non-secure prompts, we employ GPT-4 with 8k context lengths via OpenAI API [52]
B. Finding Security Vulnerabilities in GitHub Copilot
Here, we evaluate the capability of our FS-Code approach in finding security vulnerabilities of the black-box commercial model GitHub Copilot. GitHub Copilot employs Codex family models [15] via OpenAI APIs. This AI programming assistant uses a particular prompt structure to complete the given codes. This includes suffix and prefix of the user’s code together with information about other written functions [63]. The exact structure of this prompt is not publicly documented. We evaluate our FS-Code approach by providing five few-shot prompts for different CWEs (following our settings in previous experiments). As we do not have access to the GitHub Copilot model or their API, we manually query GitHub Copilot to generate non-secure prompts and codes via the available Visual Studio Code extension [9]. Due to the labor-intensive work in generating the non-secure prompts and codes, we provide the results for the first four of thirteen representative CWEs. These CWEs include CWE-020, CWE-022, CWE-078, and CWE-079 (see Table I for a description of these CWEs). In the process of generating non-secure prompts and the code, we query GitHub Copilot to provide the completion for the given sequence of the code. In each query, GitHub Copilot returns up to 10 outputs for the given code sequence. GitHub Copilot does not return duplicate outputs; therefore, the output could be less than 10 in some cases. To generate non-secure prompts, we use the same constructed few-shot prompts that we use in our FS-Code approach. After generating a set of non-secure prompts for each CWE, we query GitHub Copilot to complete the provided non-secure prompts and then use CodeQL to analyze the generated codes.
Table VII provides the results of generated vulnerable codes by GitHub Copilot using our FS-Code approach. The results are the number of codes with at least one vulnerability. In total, we generate 783 codes using 109 prompts for all four CWEs. In Table VII, column 2 to 5 provides results for different CWEs, and column 6 provide the sum of the codes with other CWEs that CodeQL detects. The last column provides the sum of the codes with at least one security vulnerability. In Table VII, we
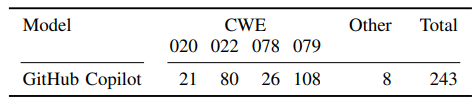
observe that our approach is also capable of testing a black-box commercial model’s potential in generating vulnerable codes. We provide vulnerable code examples generated by GitHub Copilot in Appendix B.
Authors:
(1) Hossein Hajipour, CISPA Helmholtz Center for Information Security ([email protected]);
(2) Keno Hassler, CISPA Helmholtz Center for Information Security ([email protected]);
(3) Thorsten Holz, CISPA Helmholtz Center for Information Security ([email protected]);
(4) Lea Schonherr, CISPA Helmholtz Center for Information Security ([email protected]);
(5) Mario Fritz, CISPA Helmholtz Center for Information Security ([email protected]).
This paper is
[1] Recently, OpenAI deprecated the API of the Codex model.